Auch wenn der Workshop vielleicht bisher nicht den Eindruck gemacht hat - R ist natürlich vor allem als Sprache zur Vorbereitung und Durchführung von statistischen Analysen gedacht.
Die meisten grundlegenden Analysen lassen sich natürlich - genau wie das meiste der Inhalte die bisher Thema waren - mit base-R durchführen.
Im Kosmos des tidyverse hat sich aber auch hier eine Reihe an Paketen angesammelt, die viele Auswertungen streamlinen, leichter lesbarer machen und in einer gemeinsamen Sprache ausdrücken. Die unter dem Namen tidymodels gesammelten Pakete bieten dabei Helper für Inferenz-Statistik und Machine Learning-Anwendungen in der uns jetzt ja schon bekannten tidy-Schreibweise - also als eine Reihe von in pipelines verkett-baren Verben. Wie im tidyverse lässt sich auch diese Funktionssammlung mit einem Call laden:
── Conflicts ───────────────────────────────────────── tidymodels_conflicts() ──
✖ purrr::discard() masks scales::discard()
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
✖ recipes::step() masks stats::step()
• Learn how to get started at https://www.tidymodels.org/start/
Für schon routinierte Nutzer von R ist dabei die größte Umstellung, dass Modelle nicht mehr wie folgt in einer Zeile definiert werden. Im datasets-Paket wird der Datensatz Sacramento mitgeliefert, der Wohnungspreise in Sacramento beinhaltet:
Und um inferenzstatistische Kennwerte zu erhalten könnten wir zum Beispiel summary aufrufen:
lm(price ~ sqft + beds, data = Sacramento) %>%summary()
Call:
lm(formula = price ~ sqft + beds, data = Sacramento)
Residuals:
Min 1Q Median 3Q Max
-200938 -52196 -9148 37268 620281
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 60850.544 10424.530 5.837 7.33e-09 ***
sqft 161.336 5.339 30.218 < 2e-16 ***
beds -26035.145 4366.612 -5.962 3.53e-09 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 82610 on 929 degrees of freedom
Multiple R-squared: 0.604, Adjusted R-squared: 0.6031
F-statistic: 708.5 on 2 and 929 DF, p-value: < 2.2e-16
Die Logik von tidymodels ist hierbei näher an ggplot2. Wir initiieren ein Modell aus der Familie, das wir fitten wollen und geben dann an, auf welche Daten wir dieses fitten wollen. Dazu übergeben wir die erstellte Modell-Instanz an die fit-Funktion mit den gesetzten Parametern:
Der Schritt der anfänglichen Modelldefinition scheint erstmal mehr Aufwand zu sein - der Vorteil wird aber deutlich, wenn ich mich entscheide eine andere Modell-Architektur zur Lösung der Regression nutzen möchte.
Um statt einer least-squares-Regression eine regularisiertes Regressionsmodell einzusetzen, da ich befürchte dass Anzahl der Schlafzimmer und Größe der Wohnung korreliert sind, muss ich nur eine Kleinigkeit am Modell ändern:
Oder aber ich überlege mir, dass die Zusammenhänge sicher deutlich komplizierter sind und sich das Problem nur mit einem Deep-Learning-Ansatz1 lösen lässt - also nehme ich Keras als engine:
1 wenn man einen Hidden Layer mit einem Neuron denn Deep nennen kann
Aber wenn ich schon bei Keras bin, warum dann nicht mit einem größeren Layer? Und warum lineare Aktivierung, wenn ich schon ein Deep-Learning-Backend bemühe?
Je nach Modell sind die daraus resultierenden, interpretier- und testbaren Parameter natürlich andere.
Modelltypen, Modes und Engines
Die Modelldefinition funktioniert in tidymodels über das parsnip-Paket. Die Syntax besteht auf der Modellseite dabei immer aus einem Modelltyp, im Beispiel linear_reg.
Dabei gibt es für so gut wie jeden Anwendungsfall von statistischer oder ML-Modellierung einen Modelltyp, der das Problem abzubilden versucht. 2
2 Im mit parsnip gelieferten Datensatz model_db ist eine (so weit ich das richtig sehe) nicht vollständige Liste der möglichen Modelle - hier werden allein 37 verschiedene Modelle gelistet.
3 Für die partykit-engine sind die Zusatzpakete partykit und bonsai nötig.
Ein anderes Beispiel für einen Modelltypen ist ein rand_forest. Um unser Preis-Problem zu lösen könnten wir den Aufruf wie folgt gestalten: 3
Random Forests können sowohl Klassifikations- als auch Regressions-Probleme lösen. Mit dem Zusatz set_mode zur Pipeline können wir deshalb spezifizieren, welche Art von Problem mit dem Modell gefittet werden soll.
Nach Definition von Modelltyp und mode folgt eine engine, mit der das Problem gelöst werden soll. In den Beispielen waren die engines erst lm aus stats, dann glmnet aus dem gleichnamigen Paket und abschließend der Wrapper keras_mlp um ein Keras-Netz aus dem parsnip-Paket. Zuletzt kam jetzt noch ein cforest aus dem partykit dazu.
parsnip macht mit den Anweisungen nichts anderes, als daraus einen dem Paket angemessenen Template-Call zu formulieren. Diesen template-Call kann man sich exemplarisch für das zweite Beispiel wie folgt angucken:
glmnet_model %>%translate()
Linear Regression Model Specification (regression)
Main Arguments:
penalty = 0.95
mixture = 0.5
Computational engine: glmnet
Model fit template:
glmnet::glmnet(x = missing_arg(), y = missing_arg(), weights = missing_arg(),
alpha = 0.5, family = "gaussian")
Für x, y und weights werden Platzhalter eingefügt, die dann im fit-Aufruf aufgefüllt werden.
Im Output sieht man auch, welche Werte für die so genannten Main-Argumente gesetzt sind. parsnip unterscheidet nämlich zwischen denjenigen Parametern, die für viele oder gar alle einem Modelltyp angehörigen Modelle nötig sind und vereinheitlicht deren Aufruf. Diese verpflichtenden Modellparameter, z.B. der Grad der Regularisierung bei der linearen Regression, oder auch die Anzahl der zu trainierenden Bäume in einem Random Forest, werden dann direkt im ersten Modell-Call angegeben.
Dann gibt es aber noch für jede engine spezifische Argumente, deren Setzen für einen Großteil der anderen engines keinen Sinn ergäbe. Diese Engine-arguments können im set_engine-Call übergeben werden. So können wir unserer glmnet-Regression zum Beispiel die (zumindest diskutable) Anweisung auf den Weg geben, die Mietpreise als poisson-verteilt anzunehmen:
glmnet_model <-linear_reg(penalty =0.95, mixture =0.5) %>%set_engine('glmnet', family ='poisson')glmnet_fit <- glmnet_model %>%fit(price ~ sqft + beds, data = Sacramento)tidy(glmnet_fit)
Filtern Sie den Datensatz so, dass nur das Jahr 2019 vorliegt.
Fitten Sie die Daten mit zwei linearen Regressionsmodellen, einmal mit lm und einmal mit glm als engine. Setzen Sie für das quasi-Modell die family auf “quasi”. Dabei soll in beiden Fällen die mittlere Lebenserwartung als Kriterium mit dem Alkoholkonsum, dem GDP und dem Zugang zu Elektrizität vorhergesagt werden.
fit_data <- worldbank_indicators %>%filter(Year ==2019) %>%select(Lebenserwartung =`Life expectancy at birth, total (years)`,GDP =`GDP per capita (current US$)`,Zugang =`Access to electricity (% of population)`,Alkoholkonsum =`Total alcohol consumption per capita (liters of pure alcohol, projected estimates, 15+ years of age)`)lm_model <-linear_reg()lm_fit <- lm_model %>%fit(Lebenserwartung ~ Zugang + GDP + Alkoholkonsum, data = fit_data)tidy(lm_fit)
Fitten Sie die Daten mit einem Random Forest mit randomForest als engine und 200 gefitteten Bäumen.
rf_model <-rand_forest(trees =200) %>%set_mode('regression') %>%set_engine('randomForest')rf_fit <- rf_model %>%fit(Lebenserwartung ~ Zugang + GDP + Alkoholkonsum, data = fit_data)rf_fit
parsnip model object
Call:
randomForest(x = maybe_data_frame(x), y = y, ntree = ~200)
Type of random forest: regression
Number of trees: 200
No. of variables tried at each split: 1
Mean of squared residuals: 4.709591
% Var explained: 75.31
Antwort aufdecken
Fügen Sie mit predict(<Ihr Modell-fit>, new_data=<Datensatz>) und mutate drei Spalten an Ihren Datensatz an, in denen die jeweiligen Modellvorhersagen angegeben sind. Eventuell müssen Sie das Ergebnis der predict-Funktion mit unlist in einen Vektor überführen.
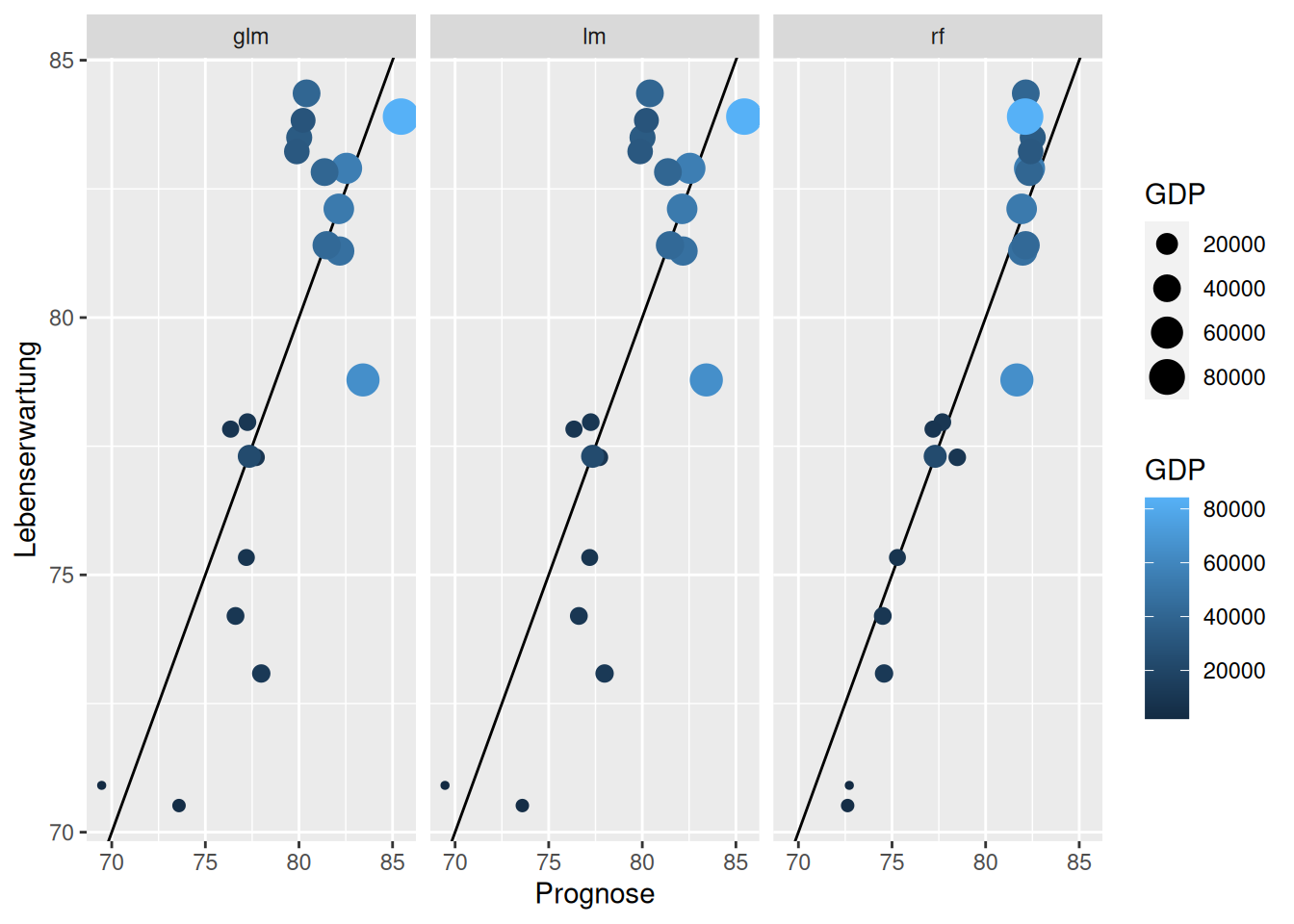
Erstellen Sie einen ggplot, der auf der x-Achse die Prognosen und auf der y-Achse die tatsächlichen Werte abträgt. Färben Sie die Punkte nach dem GDP ein, skalieren Sie auc hdie Größe der Punkte nach dem GDP. Facettieren Sie den Plot nach den drei Modellen. Fügen Sie der Grafik mit geom_abline eine schwarze Linie hinzu, die mit einer Steigung von 1 und einem Intercept von 0 eine Diagonale einzeichnet.
fit_data %>%ggplot(aes(x = Prognose, y = Lebenserwartung, color = GDP, size = GDP)) +geom_abline(intercept =0, slope =1) +geom_point() +facet_wrap(~Model)
Antwort aufdecken
Recipes und Workflows
Recipes
Neben dem Erstellen der Modelle bietet tidymodels auch pipeline-Interfaces für das standardisieren von der Vor- und Nachbereitung von Analysen. Das Vorbereiten können dabei relativ aufwändige Aufgaben des feature-Engineerings wie Methoden zur Dimensionsreduktion sein, aber auch für den inferenzstatistischen Alltag relevantere Schritte wie die Logarithmierung oder Dummyfizierung von Variablen.
Das dafür genutzte Paket heißt passenderweise recipes. Wenn wir in unserem Wohnungs-Beispiel vor der Analyse die Prädiktoren standardisieren wollen, fangen wir mit der Definition eines Rezeptes an:
Das Rezept können wir nun schrittweise ergänzen. Wenn alle Prädiktoren und vielleicht auch das Kriterium standardisieren wollen, müssen wir zuerst die Daten zentrieren und dann skalieren.
Diese Schritte sind in recipes mit den angemessen als step-Funktionen benannten Anweisungen implementiert. Für die Schritte muss jeweils angegeben werden, auf welche Teile der Designmatrix die Operationen angewandt werden sollen.
Dazu können wir die schon bekannten tidy-select-helper nutzen, wir können aber auch die sepzifischen, von recipes gelieferten Auswahl-Helfer genutzt werden. Auf der mit ?selections aufrufbaren Hifleseite sind alle aufgelistet.
Wir wollen wie gesagt alle numerischen Variablen z-transformieren, ergänzen unser Rezept also wie folgt:
Sie benötigen wieder den Datensatz der Worldbank. Erstellen Sie damit zwei Datensätze, einen mit den Daten zum Jahr 2019 und einen zum Jahr 2015. Beide Datensätze sollen die Gesamt-Lebenserwartung als Spalte mit dem Namen “target” enthalten, außerdem alle Variablen mit Ausnahme der Jahreszahl und der spezifischen Lebenserwartungen.
Erstellen Sie einen Workflow, mit dem für alle numerische Variablen alle fehlenden Werte durch die Spalten-Mittelwerte ersetzt werden. Außerdem sollen alle numerischen Werte auf einen Wertebereich von 0 bis 1 skaliert werden. Die Liste aller Steps kann Ihnen dabei helfen. Entfernen Sie außerdem mit step_zv alle Spalten, die nur einen Wert enthalten. Der Workflow soll dann alle Variablen als Kriterium nutzen um die Variable target vorherzusagen. Anfänglich soll der Workflow eine lm-engine dazu nutzen.
Fitten Sie den Workflow auf die Datensätze zu den Jahren 2015 und 2019.
lm_fit_2015 <- my_wf %>%fit(data = fit_data_2015)
Warning: Column `Electric power consumption (kWh per capita)` returned NaN. Consider
using `step_zv()` to remove variables containing only a single value.
lm_fit_2019 <- my_wf %>%fit(data = fit_data_2019)
Warning: Column `Electric power consumption (kWh per capita)` returned NaN. Consider
using `step_zv()` to remove variables containing only a single value.
Antwort aufdecken
Tauschen Sie das Modell gegen einen randomForest mit Regressions-Mode aus und fitten Sie wieder beide Modelle.
Warning: Column `Electric power consumption (kWh per capita)` returned NaN. Consider
using `step_zv()` to remove variables containing only a single value.
rf_fit_2019 <- my_wf %>%fit(data = fit_data_2019)
Warning: Column `Electric power consumption (kWh per capita)` returned NaN. Consider
using `step_zv()` to remove variables containing only a single value.
Antwort aufdecken
Erstellen Sie einen Datensatz mit allen Prognosen und targets. Pivotieren Sie diesen So, dass die targets in einer und die Prognosen in einer zweiten Spalte stehen. Nutzen Sie dazu zuerst das names_pattern-Argument der pivot_longer-Funktion und den .value-Platzhalter des names_to-Arguments. Anschließend müssen Sie vielleicht ein zweites Mal pivotieren. Lesen Sie die Hilfeseite der mape-Funktion aus dem yardstick Paket und nutzen Sie diese um die Modelle oberflächlich zu vergleichen.
Warning in predict.lm(object = object$fit, newdata = new_data, type =
"response", : prediction from rank-deficient fit; consider predict(.,
rankdeficient="NA")
Warning in predict.lm(object = object$fit, newdata = new_data, type =
"response", : prediction from rank-deficient fit; consider predict(.,
rankdeficient="NA")
results %>%group_by(name) %>%mape(target, value)
# A tibble: 2 × 4
name .metric .estimator .estimate
<chr> <chr> <chr> <dbl>
1 lm mape standard 5.33e-14
2 rf mape standard 1.44e+ 0
Antwort aufdecken
Inferenzstatistik-Pipelines mit infer
Neben der Kombination von parsnip und broom bietet tidymodels mit infer ein weiteres Paket für den inferenzstatistischen Einsatz.
infer stellt dabei ein einfaches Interface zur Formulierung von Hypothesen und deren Testung mit Bootstrapping, Permutationstests und anderen Randomisierungsverfahren zur Verfügung.
Der Ablauf sieht dabei immer wie in Abbildung 7.1 aus. Zuerst wird/werden mit specify die Variablen spezifiziert, die von Interesse sind. Daraufhin wird mit hypothesize in Textform angegeben, welche Nullhypothese man über diese Variablen testen will. Mit generate werden anschließend Daten generiert, die dieser Nullhypothese entsprechen. Abschließend kann mit calculate aus den generierten Werten eine Verteilung berechnet werden, die mit den beobachteten Werten verglichen werden kann.
Wir könnten zum Beispiel die Annahme haben, dass die Art der Mietwohnungen unterschiedlich in den verschiedenen Städten verteilt sind. Die uns interessierenden Variablen sind also type und city. Das legen wir zuallererst mit specify fest:
Sacramento %>%specify(type ~ city)
Response: type (factor)
Explanatory: city (factor)
# A tibble: 932 × 2
type city
<fct> <fct>
1 Residential SACRAMENTO
2 Residential SACRAMENTO
3 Residential SACRAMENTO
4 Residential SACRAMENTO
5 Residential SACRAMENTO
6 Condo SACRAMENTO
7 Residential SACRAMENTO
8 Residential SACRAMENTO
9 Condo RANCHO_CORDOVA
10 Residential RIO_LINDA
# ℹ 922 more rows
Unsere Nullhypothese ist unabhängigkeit, die können wir also direkt hinzufügen:
Für diese Aufgabe benötigen Sie den attrition-Datensatz, der mit tidymodels geliefert und geladen wird.
Verschaffen Sie sich einen Überblick über den Datensatz. Wir benötigen die Variable Gender und die Variable HourlyRate.
Stellen Sie eine specify -> hypothesize -> generate-Pipeline für einen t-Test auf den Unterschied in HourlyRate zwischen den Auspärgungen von Gender auf. Lesen Sie die Hilfeseiten von hypothesize und generate um den richtigen Begriff für die angemessene Nullhypothese und das angemessene Sampling-Vorgehen zu bestimmen.