Jetzt, wo wir unsere Auswertungen automatisiert und in schöne Dokumente eingebunden haben, wollen wir natürlich unsere Tabellen und Daten möglichst wenig a) händisch übertragen und b) formatieren.
Die erste Möglichkeit ist es, vor allem beim Verzicht auf quarto, alles, was an Zahlen und Tabellen für den Text anfällt, direkt in files die wir einfach einbinden können zu exportieren.
Für ANOVAs, Regressionen, t-Tests und Korrelationsanalysen gibt es im apaTables-Paket(Stanley, 2021) fertige Wrapper, die einen direkten Export der Tabellen ins doc-Format umsetzen.
Unter den folgenden Links finden sich die Dokumentation der einzelnen Funktionen aufgelistet:
Mit apa.reg.table können gewünschte Tabellen dann exportiert werden. Laut der Doku ist dabei noch wichtig, mit options eine Anzahl an Dezimalstellen vor Umwandlung in 10-er-Potenz-Notation zu setzen, die mindestens 10 ist.
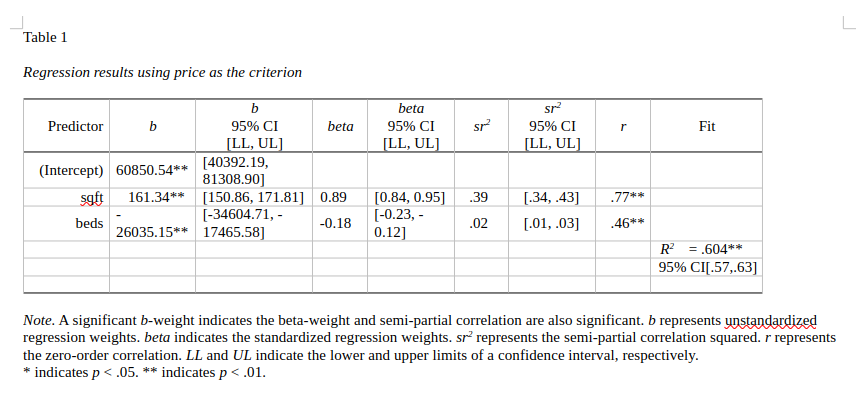
Table 1
Regression results using price as the criterion
Predictor b b_95%_CI beta beta_95%_CI sr2
(Intercept) 60850.54** [40392.19, 81308.90]
sqft 161.34** [150.86, 171.81] 0.89 [0.84, 0.95] .39
beds -26035.15** [-34604.71, -17465.58] -0.18 [-0.23, -0.12] .02
sr2_95%_CI r Fit
[.34, .43] .77**
[.01, .03] .46**
R2 = .604**
95% CI[.57,.63]
Note. A significant b-weight indicates the beta-weight and semi-partial correlation are also significant.
b represents unstandardized regression weights. beta indicates the standardized regression weights.
sr2 represents the semi-partial correlation squared. r represents the zero-order correlation.
Square brackets are used to enclose the lower and upper limits of a confidence interval.
* indicates p < .05. ** indicates p < .01.
Das table_number-Argument setzt dabei nur die Zahl in der Tabellen-Überschrift.
Wenn wir die Tabelle in ein externes file exportieren, müssen wir sie aber natürlich am Ende wieder kopieren, um sie in unsere Berichte zu kopieren.
Angenehmer wäre es natürlich, wenn wir die Tabellen direkt in unser quarto-Dokument einbinden könnten.
apaTables unterstützt diese Möglichkeit in der aktuellen Version 3.0.0 - auf Cran ist die neueste Version aber leider die 2.0.8, die diese Funktionalität noch nicht unterstützt. Sollte diese Lösung geünscht sein, lässt sich die neuere Version wie folgt direkt von github installieren:
Erstellen Sie eine Tabelle mit den deskriptiven Kennwerten der Blütenblatt-Länge pro Spezies im iris-Datensatz mit apaTables. Gucken Sie sich dafür die Dokumentation der apa.1way.table-Funktion an.
apa.1way.table(iv=Species, dv=Petal.Length, data = iris)
Descriptive statistics for Petal.Length as a function of Species.
Species M SD
setosa 1.46 0.17
versicolor 4.26 0.47
virginica 5.55 0.55
Note. M and SD represent mean and standard deviation, respectively.
Antwort aufdecken
Aufgabe 2
Benutzen Sie die apa.cor.table-Funktion um eine Korrelationsanalyse für alle numerischen Variablen im iris-Datensatz durchzuführen.
apa.cor.table(iris)
Means, standard deviations, and correlations with confidence intervals
Variable M SD 1 2 3
1. Sepal.Length 5.84 0.83
2. Sepal.Width 3.06 0.44 -.12
[-.27, .04]
3. Petal.Length 3.76 1.77 .87** -.43**
[.83, .91] [-.55, -.29]
4. Petal.Width 1.20 0.76 .82** -.37** .96**
[.76, .86] [-.50, -.22] [.95, .97]
Note. M and SD are used to represent mean and standard deviation, respectively.
Values in square brackets indicate the 95% confidence interval.
The confidence interval is a plausible range of population correlations
that could have caused the sample correlation (Cumming, 2014).
* indicates p < .05. ** indicates p < .01.
Antwort aufdecken
Tabellen mit flextable
Eine andere Möglichkeit um Tabellen zu erstellen, die via cran verfügbar ist, ist das Paket flextable(Gohel & Skintzos, 2023).
Im Gegensatz zu apaTables kann in diesem Framework alles in eine Tabelle gerendert werden, die Tabellen können außerdem sehr frei gestaltet werden. Dafür gibt es aber nicht wirklich Standards wie z.B. Formatierung nach APA.
Um die Funktionalität auszuprobieren, wird im Folgenden beispielhaft eine Tabelle grob an APA orientiert formatiert.
An Tabellen direkt wird in den Guidelines folgende Anforderungen gestellt:
Jede Spalte muss eine Überschrift haben, auch die “stub”-Spalte
die Überschriften müssen zentriert sein
der Inhalt der “stub”-Spalte muss linksbündig sein
Alle Spalten sollen zentriert sein, es sei denn der Inhalt ist linksbündig besser lesbar (z.B. bei Textspalten)
Anforderungen an Abstand und Schriftgröße in der Tabelle
Außerdem kommen noch die folgenden Anforderungen an die Formatierung statistischer Ergebnisse1 hinzu:
Zahlen sollen auf den Wert gerundet werden, bei dem die Präzision erhalten wird
Werte die nicht größer als 1 werden können sollen keine Null vor dem Komma haben
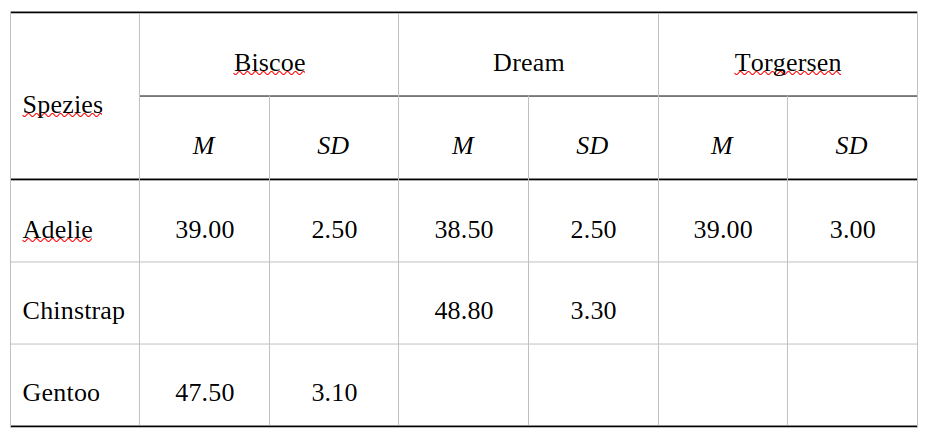
Fangen wir mit der Formatierung der Nummern an. Als Beispiel haben wir die folgende Tabelle, in der die mittlere Schnabellänge und Standardabweichung pro Pinguin-Spezies und Beobachtungsort aus dem palmerpenguins-Datensatz abgetragen sind:
summary_table <- palmerpenguins::penguins %>%group_by(species, island) %>%summarise(across(matches("bill_length_mm"),.fns =list(M = \(x) mean(x, na.rm = T),SD = \(x) sd(x, na.rm = T) ),.names ="{.col}_{.fn}")) %>%# Damit Funktion hinten stehtpivot_wider(names_from ='island',values_from =3:4,names_glue ="{island}_{.value}") # Damit Insel vorne steht
`summarise()` has grouped output by 'species'. You can override using the
`.groups` argument.
summary_table
# A tibble: 3 × 7
# Groups: species [3]
species Biscoe_bill_length_m…¹ Dream_bill_length_mm_M Torgersen_bill_lengt…²
<fct> <dbl> <dbl> <dbl>
1 Adelie 39.0 38.5 39.0
2 Chinstrap NA 48.8 NA
3 Gentoo 47.5 NA NA
# ℹ abbreviated names: ¹Biscoe_bill_length_mm_M, ²Torgersen_bill_length_mm_M
# ℹ 3 more variables: Biscoe_bill_length_mm_SD <dbl>,
# Dream_bill_length_mm_SD <dbl>, Torgersen_bill_length_mm_SD <dbl>
Zuerstmal sortieren wir die Spalten so, dass Pro Ort erst Mittelwert, dann SD steht:
Im Abschnitt zu quarto haben wir ja schon die chunk-Optionen zur Einbindung von Grafiken im Text besprochen. Ähnliche Optionen gibt es auch für Tabellen in quarto-Dokumenten.
Auch bei Tabellen muss, damit die Tabelle referenziert werden kann und numeriert wird, eine label-Option gesetzt werden. Statt dem Präfix “fig” müssen wir bei Tabellen aber den Präfix “tbl” vorstellen.
Damit sähe ein Chunk mit der Tabelle von gerade wie folgt aus:
Tab 9.1: Mittelwerte und Streuungen der Schnabellängen der beobachteten Pinguin-Populationen aufgeteilt nach Spezies und Insel.
Spezies
Biscoe
Dream
Torgersen
M
SD
M
SD
M
SD
Adelie
39.00
2.50
38.50
2.50
39.00
3.00
Chinstrap
48.80
3.30
Gentoo
47.50
3.10
Aufgaben
Aufgabe 1:
Bauen Sie die mit apaTables in Aufgabe 1 im Abschnitt zu apaTables gebaute Tabelle mit flextable nach und fügen diese zu dem bereits erstellten quarto-Dokument hinzu. Sie können gern auf die Note am unteren Rand verzichten. Oder sie lesen die Dokumentation von add_footer_lines und fügen die Notiz hinzu.
Der Code-Chunk könnte so oder so ähnlich aussehen:
#| label: tbl-irisSummary
#| tbl-cap: Descriptive statistics for Petal.Length as a function of Species.
iris %>%
group_by(Species) %>%
summarise(M = mean(Petal.Length), SD = sd(Petal.Length)) %>%
flextable() %>%
italic(part ="header", i= 1, j = 2:3) %>%
theme_apa() %>%
hline(i = 1, j = -1,part = 'header',
border= list(width = 0.1, color = "black", style = "solid")) %>%
align_text_col() %>%
add_footer_lines('Note. M and SD represent mean and standard deviation, respectively.')
Das Ergebnis sieht dann so aus:
iris %>%group_by(Species) %>%summarise(M =mean(Petal.Length), SD =sd(Petal.Length)) %>%flextable() %>%italic(part ="header", i=1, j =2:3) %>%theme_apa() %>%hline(i =1, j =-1,part ='header', border=list(width =0.1, color ="black", style ="solid")) %>%align_text_col() %>%add_footer_lines('Note. M and SD represent mean and standard deviation, respectively.')
Tab 9.2: Descriptive statistics for Petal.Length as a function of Species.
Species
M
SD
setosa
1.46
0.17
versicolor
4.26
0.47
virginica
5.55
0.55
Note. M and SD represent mean and standard deviation, respectively.
Antwort aufdecken
Aufgabe 2:
Überfliegen Sie das Kapitel zu visuellen Eigenschaften im flextable-Buch und machen Sie die Tabelle so bunt, wie Ihre Augen es aushalten. Ändern Sie sonst noch gern alles, was die Erfahrung weniger angenehm macht.
tab = iris %>%group_by(Species) %>%summarise(M =mean(Petal.Length), SD =sd(Petal.Length)) %>%flextable() %>%italic(part ="header", i=1, j =2:3) %>%theme_apa() %>%hline(i =1, j =-1,part ='header', border=list(width =0.1, color ="black", style ="solid")) %>%align_text_col() %>%add_footer_lines('Note. M and SD represent mean and standard deviation, respectively.') %>%bg(bg ="hotpink", part ="all") %>%bg(bg ="darksalmon", part ="header")%>%bg(bg ="violetred", part ="footer")rows =rep(1:3, times =3)cols =rep(1:3, each =3)colors =c('cyan', 'lawngreen', 'firebrick1', 'mediumorchid')for(i in1:9){ color <- colors[round(sqrt(rows[i]**2+ cols[i]**2))] tab <- tab %>%style(rows[i], cols[i], fp_text_default(shading.color = color))}tab
Tab 9.3: Descriptive statistics for Petal.Length as a function of Species.
Species
M
SD
setosa
1.46
0.17
versicolor
4.26
0.47
virginica
5.55
0.55
Note. M and SD represent mean and standard deviation, respectively.
Antwort aufdecken
Ergebnisse mit papaja
Im Gegensatz zu den beiden bisher vorgestellten Paketen ist papaja(Aust & Barth, 2023) nicht nur ein Paket für Tabellen, sondern ein framework zur Erstellung ganzer Berichte. Mit papaja erstellte RMarkdown-Dokumente werden direkt vollständig in APA-Format gerendert2. Außerdem gibt es noch einen ganzen Haufen an Plots, die von papaja angeboten werden.
2 Rmarkdown ist der Vorgänger von quarto. Da quarto in Zukunft wesentlich mehr Support und Features verspricht, werden in diesem Workshop die papaja-Rmarkdown-Dokumente ausgelassen.
Für diesen Workshop sind aber zwei Features besonders interessant:
apa_print und apa_table. In beide Funktionen lassen sich Ergebnisse von einer Reihe von statistischen Ergebnissen übergeben und Inline-Ergebnis-Prints und Tabellen erstellen.
Am Beispiel der linearen Regression vom Anfang des Abschnitts zu tidymodels, könnte das Vorgehen wie folgt aussehen. Zuerst erstellen wir unseren Modell-Fit:
Im Print sehen wir schon als Inline-Code formatierte Strings, die wir zum Beispiel so in den Text einfügen können:
Der Beitrag der Wohnungsgröße zum Modell zur Aufklärung des Wohnungspreises war signifikant von 0 unterschiedlich ($b = 161.34$, 95\% CI $[150.86, 171.81]$, $t(929) = 30.22$, $p < .001$).
Im Text sähe der Satz dann wie folgt aus:
Der Beitrag der Wohnungsgröße zum Modell zur Aufklärung des Wohnungspreises war signifikant von 0 unterschiedlich (\(b = 161.34\), 95% CI \([150.86, 171.81]\), \(t(929) = 30.22\), \(p < .001\)).
Den Output von apa_print können wir mit apa_table dann auch direkt als Tabelle rendern:
lm_fit$fit %>%apa_print() %>%apa_table()
(#tab:unnamed-chunk-26)
Predictor
\(b\)
95% CI
\(t\)
\(\mathit{df}\)
\(p\)
Intercept
60,850.54
[40,392.19, 81,308.90]
5.84
929
< .001
Sqft
161.34
[150.86, 171.81]
30.22
929
< .001
Beds
-26,035.15
[-34,604.71, -17,465.58]
-5.96
929
< .001
Der Output ist dabei eine markdown-Tabelle. Das heißt das unsere Formatierungsmöglichkeiten aus dem Abschnitt zu flextable auch hier funktionieren. Der folgende Chunk:
#| label: tbl-papajaModelfit
#| tbl-cap: Tabelle mit den Ergebnissen der Beispielregression
lm_fit$fit %>%
apa_print() %>%
apa_table()
wird zu:
Tab 9.4: Tabelle mit den Ergebnissen der Beispielregression
(#tab:tbl-papajaModelfit)
Predictor
\(b\)
95% CI
\(t\)
\(\mathit{df}\)
\(p\)
Intercept
60,850.54
[40,392.19, 81,308.90]
5.84
929
< .001
Sqft
161.34
[150.86, 171.81]
30.22
929
< .001
Beds
-26,035.15
[-34,604.71, -17,465.58]
-5.96
929
< .001
Aufgaben
Aufgabe 1:
Rechnen Sie einen t-Test (t.test) mit der Breite der Blütenblätter als AV und den Spezies setosa und versicolor als Gruppen.