Wie am Anfang gesagt wollen wir möglichst vermeiden, Tabellen und Daten a) händisch zu übertragen und b) zu formatieren.
Im besten Fall exportieren wir also alles was an Zahlen und Tabellen für den Text anfällt direkt in files, die wir einfach einbinden können.
Für die ANOVAs, Regressionen, t-Tests und Korrelationsanalysen gibt es im apaTables-Paket fertige Wrapper, die einen direkten Export der Tabellen ins RTF-Format umsetzen.
Unter den folgenden Links findet Ihr die Dokumentation der einzelnen Funktionen aufgelistet:
Außerdem sind im Tutorial Beispiele für alle implementierten Verfahren und Tabellen zu finden.
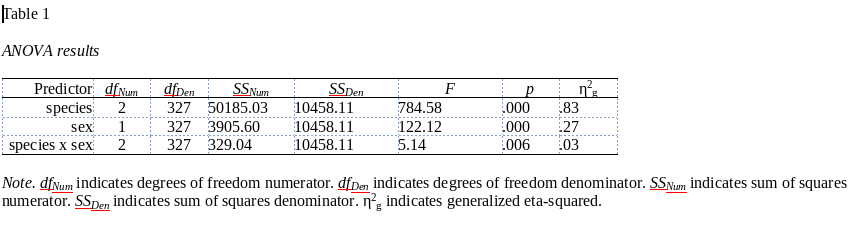
Wir können zum Beispiel mit ezAnova eine Varianzanalyse für unsere Pinguine durchführen, bei der wir Pinguin-Geschlecht und Spezies als UVs und die Flossenlänge als AV nutzen:
Warning: You have removed one or more levels from variable "sex". Refactoring
for ANOVA.
Warning: Data is unbalanced (unequal N per group). Make sure you specified a
well-considered value for the type argument to ezANOVA().
Coefficient covariances computed by hccm()
$ANOVA
Effect DFn DFd SSn SSd F p p<.05
1 species 2 327 50185.0266 10458.11 784.582911 1.569568e-125 *
2 sex 1 327 3905.6038 10458.11 122.118894 2.461150e-24 *
3 species:sex 2 327 329.0425 10458.11 5.144186 6.314424e-03 *
ges
1 0.82754673
2 0.27190772
3 0.03050319
$`Levene's Test for Homogeneity of Variance`
DFn DFd SSn SSd F p p<.05
1 5 327 141.5881 3845.9 2.407723 0.03652301 *
Mit apa.ezANOVA.table können gewünschte Tabellen dann exportiert werden. Laut der Doku ist dabei noch wichtig, mit options eine Anzahl an Dezimalstellen vor Umwandlung in 10-er-Potenz-Notation zu setzen, die mindestens 10 ist.
Das ist natürlich schon schön und praktisch wenn wir uns englische Tabellen für die implementierten Analysen ausgeben lassen wollen. Aber wie können wir eigene Tabellen nach APA-Richtlinien-konform exportieren?
Tabellen mit flextable
Was sind die Anforderungen an Tabellen laut APA? Konsultieren wir nochmal Julias1 Folien (Abbildung 9.2).
Abb 9.2: Checklist für Tabellen aus Julias Folien
Unsere Tabellen müssen also die folgenden Anforderungen erfüllen:
Jede Spalte muss eine Überschrift haben
die Überschriften müssen zentriert sein
Außerdem kommen noch die folgenden Anforderungen an die Formatierung statistischer Ergebnisse2 hinzu:
Namen statistischer Kennwerte sollen kursiv sein
Zahlen sollen auf den Wert gerundet werden, bei dem Präzision erhalten wird
Werte die nicht größer als 1 werden können sollen keine Null vor dem Komma haben
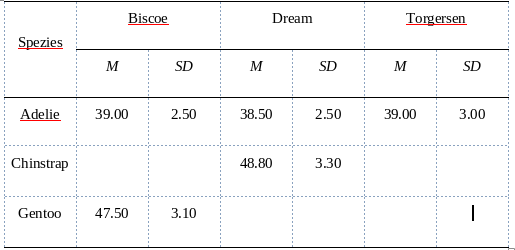
Fangen wir mit der Formatierung der Nummern an. Als Beispiel haben wir die folgende Tabelle, in der die mittlere Schnabellänge und Standardabweichung pro Pinguin-Spezies und Beobachtungsort abgetragen sind:
summary_table <- palmerpenguins::penguins %>%group_by(species, island) %>%summarise(across(matches("bill_length_mm"),.fns =list(M = \(x) mean(x, na.rm = T),SD = \(x) sd(x, na.rm = T) ),.names ="{.col}_{.fn}")) %>%# Damit Funktion hinten stehtpivot_wider(names_from ='island',values_from =3:4,names_glue ="{island}_{.value}") # Damit Insel vorne steht
`summarise()` has grouped output by 'species'. You can override using the
`.groups` argument.
summary_table
# A tibble: 3 × 7
# Groups: species [3]
species Biscoe_bill_length_m…¹ Dream_bill_length_mm_M Torgersen_bill_lengt…²
<fct> <dbl> <dbl> <dbl>
1 Adelie 39.0 38.5 39.0
2 Chinstrap NA 48.8 NA
3 Gentoo 47.5 NA NA
# ℹ abbreviated names: ¹Biscoe_bill_length_mm_M, ²Torgersen_bill_length_mm_M
# ℹ 3 more variables: Biscoe_bill_length_mm_SD <dbl>,
# Dream_bill_length_mm_SD <dbl>, Torgersen_bill_length_mm_SD <dbl>
Zuerstmal sortieren wir die Spalten so, dass Pro Ort erst Mittelwert, dann SD steht:
Aber da muss ich ja die Beschreibung doch noch nachträglich einfügen! Und was soll ich mit 15 einzelnen docs, dann muss ich ja doch alles rüberkopieren!
Natürlich gibt es da auch eine Lösung! Auftritt quarto.